JS设计模式探索
单例模式
- 保证一个类仅有一个实例,并提供一个访问它的全局访问点
- 在实际开发中,我们经常需要使用一些全局唯一的对象,比如数据库连接、线程池、缓存等。如果这些对象被多次实例化,不仅会占用过多的内存资源,而且可能会导致数据不一致的问题。因此,我们需要使用单例模式来保证这些对象的唯一性。
class Subject {
constructor() {
this.observers = [];
}
addObserver(observer) {
this.observers.push(observer);
}
removeObserver(observer) {
this.observers = this.observers.filter(obs => obs !== observer);
}
notify(data) {
this.observers.forEach(observer => observer.update(data));
}
}
class Observer {
update(data) {
console.log(`Received data: ${data}`);
}
}
const subject = new Subject();
const observerA = new Observer();
const observerB = new Observer();
subject.addObserver(observerA);
subject.addObserver(observerB);
subject.notify("Hello, Observers!");
// 输出:
// Received data: Hello, Observers!
// Received data: Hello, Observers!不足之处:
- 没有什么封装性,所有的属性方法都是暴露的。
- 全局变量很容易造成命名空间污染。
- 对象一开始变创建,万一我们用不上就浪费了。
const person = function(){
// 这里声明私有变量和方法;
const privateVariable = '私有的外面获取不到';
function showPrivate(){
console.log(privateVariable);
}
//公有的变量和方法(可以访问私有变量和方法);
return {
publicMethod: function(){
showPrivate();
},
publicVar: '共有的外面能直接获取'
}
}
const single = person();
single.publicMethod(); // '私有的外面获取不到'
console.log(single.publicVar); // '共有的外面能直接获取'策略模式
根据不同参数可以命中不同的策略
JavaScript 中的策略模式 观察如下获取年终奖的 demo, 根据不同的参数(level)获得不同策略方法(规则), 这是策略模式在 JS 比较经典的运用之一。
function calculateBonus(salary, performance) {
let bonus = 0;
if (performance === 'A') {
bonus = salary * 4;
} else if (performance === 'B') {
bonus = salary * 3;
} else if (performance === 'C') {
bonus = salary * 2;
} else {
console.log('Invalid performance level.');
}
return bonus;
}
const salary = 5000;
const performanceA = 'A';
const performanceB = 'B';
const performanceC = 'C';
console.log(`员工绩效为A,年终奖为:${calculateBonus(salary, performanceA)}`);
console.log(`员工绩效为B,年终奖为:${calculateBonus(salary, performanceB)}`);
console.log(`员工绩效为C,年终奖为:${calculateBonus(salary, performanceC)}`);
// 策略模式
const calculateBonus = {
A: function (salary) {
return salary * 4;
},
B: function (salary) {
return salary * 3;
},
C: function (salary) {
return salary * 2;
},
};
// 计算总绩效
function salaryCalculate(level, salary) {
return calculateBonus[level] && calculateBonus[level](salary);
}
console.log(salaryCalculate("A", 12000));
console.log(salaryCalculate("B", 12500));如果希望计算算法隐藏起来,那么可以借助 IIFE 使用闭包的方式,这时需要添加增加策略的入口,以方便扩展:
const calculateBonus = (function () {
const calculateBonusMap = {
A: function (salary) {
return salary * 4;
},
B: function (salary) {
return salary * 3;
},
C: function (salary) {
return salary * 2;
},
};
return {
salaryCalculate: function (level, salary) {
return calculateBonusMap[level] && calculateBonusMap[level](salary);
},
addStrategy: function (level, fn) {
// 注册新计算方式
if (calculateBonusMap[level]) return;
calculateBonusMap[level] = fn;
},
};
})();
console.log(calculateBonus.salaryCalculate("A", 12000));
console.log(calculateBonus.salaryCalculate("B", 12500));
calculateBonus.addStrategy("E", (salary) => {
return salary * 0.5;
});
console.log(calculateBonus.salaryCalculate("E", 12500));表单验证是一个常见的应用场景,而策略模式可以很好地应用于表单验证的实现
// 定义表单验证策略对象
const strategies = {
isNonEmpty(value, errorMsg) {
if (value === '') {
return errorMsg;
}
},
isEmail(value, errorMsg) {
const emailReg = /^\w+([-+.]\w+)*@\w+([-.]\w+)*.\w+([-.]\w+)*$/;
if (!emailReg.test(value)) {
return errorMsg;
}
},
minLength(value, length, errorMsg) {
if (value.length < length) {
return errorMsg;
}
},
};
// 表单验证类
class Validator {
constructor() {
this.rules = [];
}
addRule(value, rule, errorMsg) {
this.rules.push(() => strategies[rule](value, errorMsg));
}
validate() {
for (let rule of this.rules) {
const errorMsg = rule();
if (errorMsg) {
return errorMsg;
}
}
}
}
// 使用策略模式进行表单验证
const validator = new Validator();
validator.addRule('example@example.com', 'isNonEmpty', '邮箱不能为空');
validator.addRule('example@example.com', 'isEmail', '请输入有效的邮箱地址');
const error = validator.validate();
if (error) {
console.log(error);
} else {
console.log('表单验证通过');
}工厂模式
1. 什么是工厂模式?
工厂模式就是根据不用的输入返回不同的实例,一般用来创建同一类对象,它的主要思想就是将对象的创建与对象的实现分离。
在创建对象时,不暴露具体的逻辑,而是将逻辑封装在函数中,那么这个函数就可以被视为一个工厂。工厂模式根据抽象程度的不同可以分为:简单工厂、工厂方法、抽象工厂。
2. 工厂模式的实现方式 (1)简单工厂模式
简单工厂模式又叫静态工厂模式,由一个工厂对象决定创建某一种产品对象类的实例。主要用来创建同一类对象。 下面来看一个权限管理的例子,需要根据用户的权限进行页面的渲染。所以,在不同用户权限等级的构造函数中,需要保存该用户可以访问到的页面,再根据权限进行实例化用户。
//User类
class User {
//构造器
constructor(opt) {
this.name = opt.name;
this.viewPage = opt.viewPage;
}
//静态方法
static getInstance(role) {
switch (role) {
case 'superAdmin':
return new User({ name: '超级管理员', viewPage: ['首页', '应用数据', '权限管理'] });
case 'admin':
return new User({ name: '管理员', viewPage: ['首页', '应用数据'] });
case 'user':
return new User({ name: '普通用户', viewPage: ['首页'] });
default:
throw new Error('参数错误, 可选参数:superAdmin、admin、user')
}
}
}
// 实例化对象
let superAdmin = User.getInstance('superAdmin');
let admin = User.getInstance('admin');
let normalUser = User.getInstance('user');User就是一个简单工厂,在该函数中有3个实例中分别对应不同的权限的用户。当调用工厂函数时,只需要传递superAdmin, admin, user这三个可选参数中的一个获取对应的实例对象。
简单工厂模式的优势就在于,只需要一个参数,就可以获得所需的对象,无需知道对象创建的具体细节。但是,在函数内部包含了对象所有的创建逻辑,和判断逻辑的代码,如果判断逻辑很多,或者代码逻辑很复杂,这样工厂函数就会变的很复杂,很庞大,难以维护。所以,简单工厂只适合以下情况:
- 创建的对象数量较少;
- 创建的对象的逻辑不是很复杂。
(2)工厂方法模式
工厂方法模式本意是将实际创建对象的工作放在子类中,这样核心类就变成了抽象类。但是在JavaScript中,我们无法像传统面向对象语言那样去实现创建类,所以,只要遵循它的主要思想即可。
虽然ES6也没有实现abstract,但是可以使用new.target来模拟出抽象类。new.target指向直接被new执行的构造函数,对new.target进行判断,如果指向了该类则抛出错误来使得该类成为抽象类。
new.target属性允许你检测函数或构造方法是否是通过new运算符被调用的。在通过new运算符被初始化的函数或构造方法中,new.target返回一个指向构造方法或函数的引用。在普通的函数调用中,new.target 的值是undefined。
在上面的简单工厂模式中。每次添加一个构造函数都要修改两处代码,现在对它加以改造:
class User {
constructor(name = '', viewPage = []) {
if(new.target === User) {
throw new Error('抽象类不能实例化!');
}
this.name = name;
this.viewPage = viewPage;
}
}
class UserFactory extends User {
constructor(name, viewPage) {
super(name, viewPage)
}
create(role) {
switch (role) {
case 'superAdmin':
return new UserFactory( '超级管理员', ['首页', '应用数据', '权限管理'] );
case 'admin':
return new User({ name: '管理员', viewPage: ['首页', '应用数据'] });
case 'user':
return new UserFactory( '普通用户', ['首页'] );
default:
throw new Error('参数错误, 可选参数:superAdmin、admin、user')
}
}
}
let userFactory = new UserFactory();
let superAdmin = userFactory.create('superAdmin');
let admin = userFactory.create('admin');
let user = userFactory.create('user');工厂方法可以看做是一个实例化对象的工厂,它需要做的就是实例化对象。
(3)抽象工厂模式 上面两种方式都是直接生成实例,而抽象工厂模式并不能直接生成实例,而是用于产品类簇的创建。
在网站登录中,上面实例中的user可能使用不用的第三方登录,例如微信、QQ、微博,这三类账号就是对应的类簇。在抽象工厂中,类簇一般用于父类的定义,并在父类中定义一些抽象的方法(声明但不能使用的方法),在通过抽象工厂让子类继承父类,所以,抽象工厂实际上就是实现子类继承父类的方法。
在传统面向对象的语言中常用abstract进行声明,但是在JavaScript中,abstract是属于保留字,可以通过在类的方法中抛出错误来模拟抽象类。
function getAbstractUserFactory(type) {
switch (type) {
case 'wechat':
return UserOfWechat;
case 'qq':
return UserOfQq;
case 'weibo':
return UserOfWeibo;
default:
throw new Error('参数错误, 可选参数:wechat、qq、weibo')
}
}
let WechatUserClass = getAbstractUserFactory('wechat');
let QqUserClass = getAbstractUserFactory('qq');
let WeiboUserClass = getAbstractUserFactory('weibo');
let wechatUser = new WechatUserClass('微信张三');
let qqUser = new QqUserClass('QQ张三');
let weiboUser = new WeiboUserClass('微博张三');总结:
- 简单工厂模式又叫静态工厂方法,用来创建某一种产品对象的实例,用来创建单一对象;
- 工厂方法模式是将创建实例推迟到子类中进行;
- 抽象工厂模式是对类的工厂抽象用来创建产品类簇,不负责创建某一类产品的实例。
3. Vue中的工厂模式
(1)VNode
和原生的 document.createElement 类似,Vue 这种具有虚拟 DOM 树(Virtual Dom Tree)机制的框架在生成虚拟 DOM 的时候,提供了 createElement 方法用来生成 VNode,用来作为真实 DOM 节点的映射:
createElement('h3', { class: 'main-title' }, [
createElement('img', { class: 'avatar', attrs: { src: '../avatar.jpg' } }),
createElement('p', { class: 'user-desc' }, 'hello world')
])createElement 函数结构大概如下:
class Vnode (tag, data, children) { ... }
function createElement(tag, data, children) {
return new Vnode(tag, data, children)
}createElement 函数内会进行 VNode 的具体创建,创建的过程是很复杂的,而框架提供的 createElement 工厂方法封装了复杂的创建与验证过程,对于使用者来说就很方便了。
(2)vue-router
在Vue在路由创建模式中,也多次用到了工厂模式:
export default class VueRouter {
constructor(options) {
this.mode = mode // 路由模式
switch (mode) { // 简单工厂
case 'history': // history 方式
this.history = new HTML5History(this, options.base)
break
case 'hash': // hash 方式
this.history = new HashHistory(this, options.base, this.fallback)
break
case 'abstract': // abstract 方式
this.history = new AbstractHistory(this, options.base)
break
default:
// ... 初始化失败报错
}
}
}Vue-Router没有把工厂方法的产品创建流程封装出来,而是直接将产品实例的创建流程暴露在 VueRouter 的构造函数中,在被 new 的时候创建对应产品实例,相当于 VueRouter 的构造函数就是一个工厂方法。
如果一个系统不是单页面应用,而是多页面应用,那么就需要创建多个 VueRouter 的实例,此时 VueRouter 的构造函数也就是工厂方法将会被多次执行,以分别获得不同实例。
状态模式
状态模式 (State Pattern)允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类,类的行为随着它的状态改变而改变。
状态模式主要解决的是当控制一个对象状态的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示不同状态的一系列类中,可以把复杂的判断逻辑简化。
实现方式
定义状态接口(State Interface):在 JavaScript 中,我们可以使用类或对象字面量来定义状态接口。状态接口定义了状态类的共同方法,每个具体状态类都必须实现这些方法。
// 状态接口
class StateInterface {
handleAction() {
// 具体状态的行为逻辑
}
}
// 或者使用对象字面量
const stateInterface = {
handleAction() {
// 具体状态的行为逻辑
},
};实现具体状态类(Concrete State Class):具体状态类实现状态接口,并定义每个具体状态的行为逻辑。
// 具体状态类
class ConcreteStateA extends StateInterface {
handleAction() {
// 具体状态A的行为逻辑
}
}
class ConcreteStateB extends StateInterface {
handleAction() {
// 具体状态B的行为逻辑
}
}
// 或者使用对象字面量
const concreteStateA = {
handleAction() {
// 具体状态A的行为逻辑
},
};
const concreteStateB = {
handleAction() {
// 具体状态B的行为逻辑
},
};定义上下文类(Context Class):上下文类包含状态对象,并提供接口供客户端代码调用。上下文类将具体的状态转换逻辑封装在内部,通常会通过改变当前状态来触发不同的行为。
class Context {
constructor() {
this.state = null; // 当前状态
}
setState(state) {
this.state = state;
}
handleAction() {
this.state.handleAction();
}
}使用状态模式:在实际应用中,我们可以通过创建具体的状态对象,并将它们赋值给上下文对象来使用状态模式。
const context = new Context();
// 设置初始状态
context.setState(new ConcreteStateA());
// 调用上下文对象的方法进行具体操作
context.handleAction(); // 根据当前状态,执行对应的行为
// 状态切换
context.setState(new ConcreteStateB());
context.handleAction(); // 根据当前状态,执行对应的行为通过封装每个具体状态为单独的类,并在上下文对象中管理状态的切换,可以有效地组织和管理应用程序的不同状态。
应用场景 举一个最常见的例子,就是电商网站的订单管理,一个订单可能经历多个不同的状态,如待付款、待发货、运输中、已完成等。状态模式可以帮助我们管理和切换这些不同的订单状态,从而处理相应的逻辑。
// 定义订单状态接口
class OrderState {
// 将订单状态作为参数传入,以便在不同状态下执行相应的行为
constructor(order) {
this.order = order;
}
cancel() {
throw new Error("该状态下不可取消订单");
}
pay() {
throw new Error("该状态下不可支付订单");
}
ship() {
throw new Error("该状态下不可发货");
}
// 其他可能的订单操作...
}
// 具体订单状态类
class NewOrderState extends OrderState {
cancel() {
console.log("订单已取消");
this.order.setState(new CancelledOrderState(this.order));
}
pay() {
console.log("订单已支付");
this.order.setState(new PaidOrderState(this.order));
}
ship() {
console.log("订单未支付,无法发货");
}
}
class PaidOrderState extends OrderState {
cancel() {
console.log("订单已取消");
this.order.setState(new CancelledOrderState(this.order));
}
pay() {
console.log("订单已支付,请勿重复支付");
}
ship() {
console.log("订单已发货");
this.order.setState(new ShippedOrderState(this.order));
}
}
class ShippedOrderState extends OrderState {
cancel() {
console.log("订单已发货,无法取消");
}
pay() {
console.log("订单已支付,请勿重复支付");
}
ship() {
console.log("订单已发货,请勿重复发货");
}
// 其他可能的订单操作...
}
class CancelledOrderState extends OrderState {
cancel() {
console.log("订单已取消,请勿重复取消");
}
// 其他可能的订单操作...
}
// 订单管理类
class Order {
constructor() {
// 设置初始状态为新订单状态
this.state = new NewOrderState(this);
}
setState(state) {
this.state = state;
}
cancel() {
this.state.cancel();
}
pay() {
this.state.pay();
}
ship() {
this.state.ship();
}
// 其他可能的订单操作...
}使用示例
const order = new Order();
order.cancel(); // 输出:"该状态下不可取消订单"
order.pay(); // 输出:"订单已支付"
order.pay(); // 输出:"订单已支付,请勿重复支付"
order.ship(); // 输出:"订单已发货"
order.cancel(); // 输出:"订单已发货,无法取消"状态模式的优缺点 状态模式的优点:
- 结构相比之下清晰,避免了过多的 switch-case 或 if-else 语句的使用,避免了程序的复杂性提高系统的可维护性;
- 符合开闭原则,每个状态都是一个子类,增加状态只需增加新的状态类即可,修改状态也只需修改对应状态类就可以了;
- 封装性良好,状态的切换在类的内部实现,外部的调用无需知道类内部如何实现状态和行为的变换。
状态模式的缺点:引入了多余的类,每个状态都有对应的类,导致系统中类的个数增加。
- 状态模式: 重在强调对象内部状态的变化改变对象的行为,状态类之间是平行的,无法相互替换;
- 策略模式: 策略的选择由外部条件决定,策略可以动态的切换,策略之间是平等的,可以相互替换;
代理模式
1. 什么是代理模式?
代理模式 (Proxy Pattern)又称委托模式,它为目标对象创造了一个代理对象,以控制对目标对象的访问。
代理模式把代理对象插入到访问者和目标对象之间,从而为访问者对目标对象的访问引入一定的间接性。正是这种间接性,给了代理对象很多操作空间,比如在调用目标对象前和调用后进行一些预操作和后操作,从而实现新的功能或者扩展目标的功能。
在类似的场景中,有以下特点:
- 导演/法院(访问者)对明星/当事人(目标)的访问都是通过经纪人/律师(代理)来完成;
- 经纪人/律师(代理)对访问有过滤的功能;
2. 代理模式的实现
/* 明星 */
var SuperStar = {
name: '小鲜肉',
playAdvertisement: function(ad) {
console.log(ad)
}
}
/* 经纪人 */
var ProxyAssistant = {
name: '经纪人张某',
playAdvertisement: function(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
SuperStar.playAdvertisement(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚这里通过经纪人的方式来和明星取得联系,经纪人会视条件过滤一部分合作请求。
可以升级一下,比如如果明星没有档期的话,可以通过经纪人安排档期,当明星有空的时候才让明星来拍广告。这里通过 Promise 的方式来实现档期的安排:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime() {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log('小鲜鲜有空了')
resolve()
}, 2000) // 发现明星有空了
})
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime() // 安排上了
.then(() => SuperStar.playAdvertisement(ad))
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸这里就简单实现了经纪人对请求的过滤,对明星档期的安排,实现了一个代理对象的基本功能。
对于上面的例子,明星就相当于被代理的目标对象(Target),而经纪人就相当于代理对象(Proxy),希望找明星的人是访问者(Visitor),他们直接找不到明星,只能找明星的经纪人来进行业务商洽。主要有以下几个概念:
- Target: 目标对象,也是被代理对象,是具体业务的实际执行者;
- Proxy: 代理对象,负责引用目标对象,以及对访问的过滤和预处理;
概略图如下

ES6 原生提供了Proxy构造函数,这个构造函数让我们可以很方便地创建代理对象:
var proxy = new Proxy(target, handler);参数中 target 是被代理对象,handler 用来设置代理行为。
这里使用Proxy来实现一下上面的经纪人例子:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
scheduleFlag: false, // 档期标识位,false-没空(默认值),true-有空
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime(ad) {
const schedule = new Proxy(SuperStar, { // 在这里监听 scheduleFlag 值的变化
set(obj, prop, val) {
if (prop !== 'scheduleFlag') return
if (obj.scheduleFlag === false &&
val === true) { // 小鲜肉现在有空了
obj.scheduleFlag = true
obj.playAdvertisement(ad) // 安排上了
}
}
})
setTimeout(() => {
console.log('小鲜鲜有空了')
schedule.scheduleFlag = true // 明星有空了
}, 2000)
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸在 ES6 之前,一般是使用 Object.defineProperty 来完成相同的功能,可以使用这个 API 改造一下:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
scheduleFlagActually: false, // 档期标识位,false-没空(默认值),true-有空
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime(ad) {
Object.defineProperty(SuperStar, 'scheduleFlag', { // 在这里监听 scheduleFlag 值的变化
get() {
return SuperStar.scheduleFlagActually
},
set(val) {
if (SuperStar.scheduleFlagActually === false &&
val === true) { // 小鲜肉现在有空了
SuperStar.scheduleFlagActually = true
SuperStar.playAdvertisement(ad) // 安排上了
}
}
})
setTimeout(() => {
console.log('小鲜鲜有空了')
SuperStar.scheduleFlag = true
}, 2000) // 明星有空了
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸3. 代理模式在实战中的应用
(1)拦截器
上面使用代理模式代理对象的访问的方式,一般又被称为拦截器。
拦截器的思想在实战中应用非常多,比如我们在项目中经常使用 Axios 的实例来进行 HTTP 的请求,使用拦截器 interceptor 可以提前对 request 请求和 response 返回进行一些预处理,比如:
- request 请求头的设置,和 Cookie 信息的设置;
- 权限信息的预处理,常见的比如验权操作或者 Token 验证;
- 数据格式的格式化,比如对组件绑定的 Date 类型的数据在请求前进行一些格式约定好的序列化操作;
- 空字段的格式预处理,根据后端进行一些过滤操作;
- response 的一些通用报错处理,比如使用 Message 控件抛出错误;
除了 HTTP 相关的拦截器之外,还有路由跳转的拦截器,可以进行一些路由跳转的预处理等操作。
(2)前端框架的数据响应式化
现在的很多前端框架或者状态管理框架都使用上面介绍的 Object.defineProperty 和 Proxy 来实现数据的响应式化,比如 Vue,Vue 2.x 使用前者,而 Vue 3.x 则使用后者。
Vue 2.x 中通过 Object.defineProperty 来劫持各个属性的 setter/getter,在数据变动时,通过发布-订阅模式发布消息给订阅者,触发相应的监听回调,从而实现数据的响应式化,也就是数据到视图的双向绑定。
为什么 Vue 2.x 到 3.x 要从 Object.defineProperty 改用 Proxy 呢,是因为前者的一些局限性,导致的以下缺陷:
- 无法监听利用索引直接设置数组的一个项,例如:vm.items[indexOfItem] = newValue;
- 无法监听数组的长度的修改,例如:vm.items.length = newLength;
- 无法监听 ES6 的 Set、WeakSet、Map、WeakMap 的变化;
- 无法监听 Class 类型的数据;
- 无法监听对象属性的新加或者删除;
除此之外还有性能上的差异,基于这些原因,Vue 3.x 改用 Proxy 来实现数据监听了。当然缺点就是对 IE 用户的不友好,兼容性敏感的场景需要做一些取舍。
(3)缓存代理
在高阶函数的文章中,就介绍了备忘模式,备忘模式就是使用缓存代理的思想,将复杂计算的结果缓存起来,下次传参一致时直接返回之前缓存的计算结果。
(4)保护代理和虚拟代理
有的书籍中着重强调代理的两种形式:保护代理和虚拟代理:
- 保护代理 :当一个对象可能会收到大量请求时,可以设置保护代理,通过一些条件判断对请求进行过滤;
- 虚拟代理 :在程序中可以能有一些代价昂贵的操作,此时可以设置虚拟代理,虚拟代理会在适合的时候才执行操作。
(5)正向代理与反向代理
还有个经常用的例子是反向代理(Reverse Proxy),反向代理对应的是正向代理(Forward Proxy),他们的区别是:
- 正向代理: 一般的访问流程是客户端直接向目标服务器发送请求并获取内容,使用正向代理后,客户端改为向代理服务器发送请求,并指定目标服务器(原始服务器),然后由代理服务器和原始服务器通信,转交请求并获得的内容,再返回给客户端。正向代理隐藏了真实的客户端,为客户端收发请求,使真实客户端对服务器不可见;
- 反向代理: 与一般访问流程相比,使用反向代理后,直接收到请求的服务器是代理服务器,然后将请求转发给内部网络上真正进行处理的服务器,得到的结果返回给客户端。反向代理隐藏了真实的服务器,为服务器收发请求,使真实服务器对客户端不可见。
装饰器模式
1. 什么是装饰器模式?
装饰器模式,又名装饰者模式。它的定义是“在不改变原对象的基础上,通过对其进行包装拓展,使得原有对象可以动态具有更多功能,从而满足用户的更复杂需求”。
装饰器模式的本质是功能动态组合,即动态地给一个对象添加额外的职责,就增加功能角度来看,使用装饰器模式比用继承更为灵活。好处就是有效地把对象的核心职责和装饰功能区分开,并且通过动态增删装饰去除目标对象中重复的装饰逻辑。
我们在买房之后,就可以居住了。但是,往往会对房屋进行装饰,通水电、刷漆、铺地板、购置家具,安装家电等等。这样,就让房屋就有了各种各样的特性,刷漆、铺地板之后房子变的更美观了;摆放家具、家电之后,房屋就更加便捷了等等。但是,我们并没有改变房子是用来居住的基本功能,这就是装饰的作用。
我们好多人喜欢给手机买手机壳,装上手机壳之后,手机就变得更加耐磨,耐摔,更加好看等,但是并没有改变手机的功能,只是对其进行了装饰。
这两个例子中,都有以下特点:
- 装饰不影响原有的功能,原有功能可以照常使用;
- 装饰可以增加多个,共同给目标对象添加额外功能。
2. 装饰器模式的原理
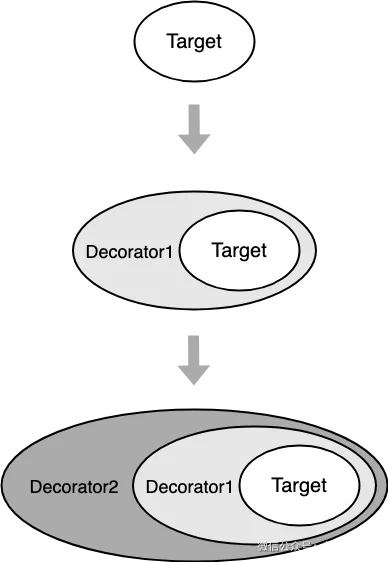
从上图看出,在表现形式上,装饰器模式和适配器模式比较类似,都属于包装模式。在装饰器模式中,一个对象被另一个对象包装起来,形成一条包装链,并增加了原先对象的功能。
3. 装饰器模式的使用场景
(1)给浏览器事件添加新功能
添加装饰器函数常被用来给原有浏览器或 DOM 绑定事件上绑定新的功能,比如在 onload 上增加新的事件,或在原来的事件绑定函数上增加新的功能,或者在原本的操作上增加用户行为埋点:
window.onload = function() {
console.log('原先的 onload 事件 ')
}
/* 发送埋点信息 */
function sendUserOperation() {
console.log('埋点:用户当前行为路径为 ...')
}
/* 将新的功能添加到 onload 事件上 */
window.onload = function() {
var originOnload = window.onload
return function() {
originOnload && originOnload()
sendUserOperation()
}
}()
// 输出: 原先的 onload 事件
// 输出: 埋点:用户当前行为路径为 ...可以看到通过添加装饰函数,为 onload 事件回调增加新的方法,且并不影响原本的功能,可以把上面的方法提取出来作为一个工具方法:
window.onload = function() {
console.log('原先的 onload 事件 ')
}
/* 发送埋点信息 */
function sendUserOperation() {
console.log('埋点:用户当前行为路径为 ...')
}
/* 给原生事件添加新的装饰方法 */
function originDecorateFn(originObj, originKey, fn) {
originObj[originKey] = function() {
var originFn = originObj[originKey]
return function() {
originFn && originFn()
fn()
}
}()
}
// 添加装饰功能
originDecorateFn(window, 'onload', sendUserOperation)
// 输出: 原先的 onload 事件
// 输出: 埋点:用户当前行为路径为 ...(2)给浏览器事件添加新功能
下面再看一个场景:点击一个按钮后,如果用户还未登录,就弹窗提示用户“您还未登录哦~”。
<body>
<button id='open'>点击打开</button>
<button id='close'>关闭弹框</button>
</body>
<script>
// 弹框创建逻辑,这里我们复用了单例模式面试题的例子
const Modal = (function() {
let modal = null
return function() {
if(!modal) {
modal = document.createElement('div')
modal.innerHTML = '您还未登录哦~'
modal.id = 'modal'
modal.style.display = 'none'
document.body.appendChild(modal)
}
return modal
}
})()
// 点击打开按钮展示模态框
document.getElementById('open').addEventListener('click', function() {
// 未点击则不创建modal实例,避免不必要的内存占用
const modal = new Modal()
modal.style.display = 'block'
})
// 点击关闭按钮隐藏模态框
document.getElementById('close').addEventListener('click', function() {
const modal = document.getElementById('modal')
if(modal) {
modal.style.display = 'none'
}
})
</script>后来因为业务需求的变更,要求在弹框被关闭后把按钮的文案改为“快去登录”,同时把按钮置灰。
这个需求更改看起来比较简单,但是,可能不止有一个按钮有这个需求,那有可能还要更该很多代码。况且,直接去修改已有的函数体的话,就违背了“开放封闭原则”;在一个函数体中写很多逻辑,就违背了“单一职责原则”。
我们要做的就是将原来的逻辑与新的逻辑分离,将旧的逻辑抽离出来:
// 将展示Modal的逻辑单独封装
function openModal() {
const modal = new Modal()
modal.style.display = 'block'
}编写新逻辑:
// 按钮文案修改逻辑
function changeButtonText() {
const btn = document.getElementById('open')
btn.innerText = '快去登录'
}
// 按钮置灰逻辑
function disableButton() {
const btn = document.getElementById('open')
btn.setAttribute("disabled", true)
}
// 新版本功能逻辑整合
function changeButtonStatus() {
changeButtonText()
disableButton()
}然后把三个操作逐个添加open按钮的监听函数里:
document.getElementById('open').addEventListener('click', function() {
openModal()
changeButtonStatus()
})这样,就实现了“只添加,不修改”的装饰器模式,使用changeButtonStatus的逻辑装饰了旧的按钮点击逻辑。
以上是ES5中的实现,ES6中,可以以一种更加面向对象化的方式去写:
// 定义打开按钮
class OpenButton {
// 点击后展示弹框(旧逻辑)
onClick() {
const modal = new Modal()
modal.style.display = 'block'
}
}
// 定义按钮对应的装饰器
class Decorator {
// 将按钮实例传入
constructor(open_button) {
this.open_button = open_button
}
onClick() {
this.open_button.onClick()
// “包装”了一层新逻辑
this.changeButtonStatus()
}
changeButtonStatus() {
this.changeButtonText()
this.disableButton()
}
disableButton() {
const btn = document.getElementById('open')
btn.setAttribute("disabled", true)
}
changeButtonText() {
const btn = document.getElementById('open')
btn.innerText = '快去登录'
}
}
const openButton = new OpenButton()
const decorator = new Decorator(openButton)
document.getElementById('open').addEventListener('click', function() {
// openButton.onClick()
// 此处可以分别尝试两个实例的onClick方法,验证装饰器是否生效
decorator.onClick()
})4. 装饰器模式的优缺点
装饰器模式的优点:
- 可维护性高: 我们经常使用继承的方式来实现功能的扩展,但这样会给系统中带来很多的子类和复杂的继承关系,装饰器模式允许用户在不引起子类数量暴增的前提下动态地修饰对象,添加功能,装饰器和被装饰器之间松耦合,可维护性好;
- 灵活性好: 被装饰器可以使用装饰器动态地增加和撤销功能,可以在运行时选择不同的装饰器,实现不同的功能,灵活性好;
- 复用性高: 装饰器模式把一系列复杂的功能分散到每个装饰器当中,一般一个装饰器只实现一个功能,可以给一个对象增加多个同样的装饰器,也可以把一个装饰器用来装饰不同的对象,有利于装饰器功能的复用;
- 多样性: 可以通过选择不同的装饰器的组合,创造不同行为和功能的结合体,原有对象的代码无须改变,就可以使得原有对象的功能变得更强大和更多样化,符合开闭原则;
装饰器模式的缺点:
- 使用装饰器模式时会产生很多细粒度的装饰器对象,这些装饰器对象由于接口和功能的多样化导致系统复杂度增加,功能越复杂,需要的细粒度对象越多;
- 由于更大的灵活性,也就更容易出错,特别是对于多级装饰的场景,错误定位会更加繁琐;
适配器模式
1. 适配器模式
适配器模式(Adapter Pattern)又称包装器模式,将一个类(对象)的接口(方法、属性)转化为用户需要的另一个接口,解决类(对象)之间接口不兼容的问题。
主要功能是进行转换匹配,目的是复用已有的功能,而不是来实现新的接口。也就是说,访问者需要的功能应该是已经实现好了的,不需要适配器模式来实现,适配器模式主要是负责把不兼容的接口转换成访问者期望的格式而已。
在生活中我们会遇到形形色色的适配器,最常见的就是转接头了,比如不同规格电源接口的转接头、3.5 毫米耳机插口转接头、DP/miniDP/HDMI/DVI/VGA 等视频转接头、电脑、手机、ipad 的电源适配器,都是属于适配器的范畴。
在类似场景中,这些例子有以下特点:
- 旧有接口格式已经不满足现在的需要;
- 通过增加适配器来更好地使用旧有接口;
2. 适配器模式的实现 下面来实现一下电源适配器的例子,使用中国插头标准:
var chinaPlug = {
type: '中国插头',
chinaInPlug() {
console.log('开始供电')
}
}
chinaPlug.chinaInPlug()
// 输出:开始供电但是出国旅游,到了日本,需要增加一个日本插头到中国插头的电源适配器,来将原来的电源线用起来:
var chinaPlug = {
type: '中国插头',
chinaInPlug() {
console.log('开始供电')
}
}
var japanPlug = {
type: '日本插头',
japanInPlug() {
console.log('开始供电')
}
}
/* 日本插头电源适配器 */
function japanPlugAdapter(plug) {
return {
chinaInPlug() {
return plug.japanInPlug()
}
}
}
japanPlugAdapter(japanPlug).chinaInPlug()
// 输出:开始供电适配器模式的原理大概如下图:
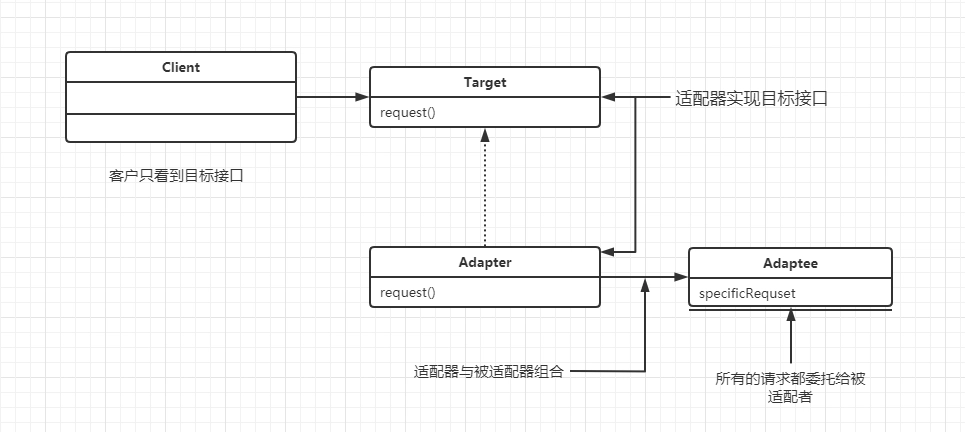
访问者需要目标对象的某个功能,但是这个对象的接口不是自己期望的,那么通过适配器模式对现有对象的接口进行包装,来获得自己需要的接口格式。
3. 适配器模式的应用
适配器模式在日常开发中还是比较频繁的,其实可能已经使用了,但却不知道原来这就是适配器模式。适配器可以将新的软件实体适配到老的接口,也可以将老的软件实体适配到新的接口,具体如何来进行适配,可以根据具体使用场景来灵活使用。
(1)业务数据适配
在实际项目中,我们经常会遇到树形数据结构和表形数据结构的转换,比如全国省市区结构、公司组织结构、军队编制结构等等。以公司组织结构为例,在历史代码中,后端给了公司组织结构的树形数据,在以后的业务迭代中,会增加一些要求非树形结构的场景。比如增加了将组织维护起来的功能,因此就需要在新增组织的时候选择上级组织,在某个下拉菜单中选择这个新增组织的上级菜单。或者增加了将人员归属到某一级组织的需求,需要在某个下拉菜单中选择任一级组织。
在这些业务场景中,都需要将树形结构平铺开,但是又不能直接将旧有的树形结构状态进行修改,因为在项目别的地方已经使用了老的树形结构状态,这时可以引入适配器来将老的数据结构进行适配:
/* 原来的树形结构 */
const oldTreeData = [
{
name: '总部',
place: '一楼',
children: [
{ name: '财务部', place: '二楼' },
{ name: '生产部', place: '三楼' },
{
name: '开发部', place: '三楼', children: [
{
name: '软件部', place: '四楼', children: [
{ name: '后端部', place: '五楼' },
{ name: '前端部', place: '七楼' },
{ name: '技术支持部', place: '六楼' }]
}, {
name: '硬件部', place: '四楼', children: [
{ name: 'DSP部', place: '八楼' },
{ name: 'ARM部', place: '二楼' },
{ name: '调试部', place: '三楼' }]
}]
}
]
}
]
/* 树形结构平铺 */
function treeDataAdapter(treeData, lastArrayData = []) {
treeData.forEach(item => {
if (item.children) {
treeDataAdapter(item.children, lastArrayData)
}
const { name, place } = item
lastArrayData.push({ name, place })
})
return lastArrayData
}
treeDataAdapter(oldTreeData)
// 返回平铺的组织结构增加适配器后,就可以将原先状态的树形结构转化为所需的结构,而并不改动原先的数据,也不对原来使用旧数据结构的代码有所影响
(2)Vue 计算属性 Vue 中的计算属性也是一个适配器模式的实例,以官网的例子为例:
<template>
<div id="example">
<p>Original message: "{{ message }}"</p> <!-- Hello -->
<p>Computed reversed message: "{{ reversedMessage }}"</p> <!-- olleH -->
</div>
</template>
<script type='text/javascript'>
export default {
name: 'demo',
data() {
return {
message: 'Hello'
}
},
computed: {
reversedMessage: function() {
return this.message.split('').reverse().join('')
}
}
}
</script>4. 源码中的适配器模式 Axios 是比较热门的网络请求库,在浏览器中使用的时候,Axios 的用来发送请求的 adapter 本质上是封装浏览器提供的 API XMLHttpRequest,可以看看源码中是如何封装这个 API 的,为了方便观看,进行了一些省略:
module.exports = function xhrAdapter(config) {
return new Promise(function dispatchXhrRequest(resolve, reject) {
var requestData = config.data
var requestHeaders = config.headers
var request = new XMLHttpRequest()
// 初始化一个请求
request.open(config.method.toUpperCase(),
buildURL(config.url, config.params, config.paramsSerializer), true)
// 设置最大超时时间
request.timeout = config.timeout
// readyState 属性发生变化时的回调
request.onreadystatechange = function handleLoad() { ... }
// 浏览器请求退出时的回调
request.onabort = function handleAbort() { ... }
// 当请求报错时的回调
request.onerror = function handleError() { ... }
// 当请求超时调用的回调
request.ontimeout = function handleTimeout() { ... }
// 设置HTTP请求头的值
if ('setRequestHeader' in request) {
request.setRequestHeader(key, val)
}
// 跨域的请求是否应该使用证书
if (config.withCredentials) {
request.withCredentials = true
}
// 响应类型
if (config.responseType) {
request.responseType = config.responseType
}
// 发送请求
request.send(requestData)
})
}可以看到这个模块主要是对请求头、请求配置和一些回调的设置,并没有对原生的 API 有改动,所以也可以在其他地方正常使用。这个适配器可以看作是对 XMLHttpRequest 的适配,是用户对 Axios 调用层到原生 XMLHttpRequest 这个 API 之间的适配层。
5. 适配器模式的优缺点
适配器模式的优点:
- 已有的功能如果只是接口不兼容,使用适配器适配已有功能,可以使原有逻辑得到更好的复用,有助于避免大规模改写现有代码;
- 可扩展性良好,在实现适配器功能的时候,可以调用自己开发的功能,从而方便地扩展系统的功能;
- 灵活性好,因为适配器并没有对原有对象的功能有所影响,如果不想使用适配器了,那么直接删掉即可,不会对使用原有对象的代码有影响;
适配器模式的缺点:会让系统变得零乱,明明调用 A,却被适配到了 B,如果系统中这样的情况很多,那么对可阅读性不太友好。如果没必要使用适配器模式的话,可以考虑重构,如果使用的话,可以考虑尽量把文档完善。
迭代器模式
1. 什么是迭代器模式?
迭代器模式 (Iterator Pattern)用于顺序地访问聚合对象内部的元素,又无需知道对象内部结构。使用了迭代器之后,使用者不需要关心对象的内部构造,就可以按序访问其中的每个元素。
银行里的点钞机就是一个迭代器,放入点钞机的钞票里有不同版次的人民币,每张钞票的冠字号也不一样,但当一沓钞票被放入点钞机中,使用者并不关心这些差别,只关心钞票的数量,以及是否有假币。
这里使用 JavaScript 的方式来点一下钞:
const bills = ['MCK013840031', 'MCK013840032', 'MCK013840033', 'MCK013840034', 'MCK013840035']
bills.forEach(function(bill) {
console.log('当前钞票的冠字号为 ' + bill)
})由于JavaScript 已经内置了迭代器的实现,所以实现起来非常简单。
2. 迭代器的简单实现
前面的 forEach 方法是在 IE9 之后才原生提供的,那么在 IE9 之前的时代里,如何实现一个迭代器呢,可以使用 for 循环自己实现一个 forEach:
var forEach = function(arr, cb) {
for (var i = 0; i < arr.length; i++) {
cb.call(arr[i], arr[i], i, arr)
}
}
forEach(['hello', 'world', '!'], function(currValue, idx, arr) {
console.log('当前值 ' + currValue + ',索引为 ' + idx)
})
// 输出: 当前值 hello,索引为 0
// 输出: 当前值 world,索引为 1
// 输出: 当前值 ! ,索引为 23. JavaScript 原生支持
随着 JavaScript 的 ECMAScript 标准每年的发展,给越来越多好用的 API 提供了支持,比如 Array 上的 filter、forEach、reduce、flat 等,还有 Map、Set、String 等数据结构,也提供了原生的迭代器支持,给开发提供了很多便利。
JavaScript 中还有很多类数组结构,比如:
arguments:函数接受的所有参数构成的类数组对象;NodeList:是 querySelector 接口族返回的数据结构;HTMLCollection:是 getElementsBy 接口族返回的数据结构;
对于这些类数组结构,可以通过一些方式来转换成普通数组结构,以 arguments 为例:
// 方法一
var args = Array.prototype.slice.call(arguments)
// 方法二
var args = [].slice.call(arguments)
// 方法三 ES6提供
const args = Array.from(arguments)
// 方法四 ES6提供
const args = [...arguments];转换成数组之后,就可以使用 JavaScript 在 Array 上提供的各种方法了。
4. ES6 中的迭代器
ES6 规定,默认的迭代器部署在对应数据结构的 Symbol.iterator 属性上,如果一个数据结构具有 Symbol.iterator 属性,就被视为可遍历的,就可以用for...of循环遍历它的成员。也就是说,for...of循环内部调用的是数据结构的Symbol.iterator 方法。
for-of 循环可以使用的范围包括 Array、Set、Map 结构、上文提到的类数组结构、Generator 对象,以及字符串。
通过 for-of 可以使用 Symbol.iterator 这个属性提供的迭代器可以遍历对应数据结构,如果对没有提供 Symbol.iterator 的目标使用for-of则会抛错:
var foo = { a: 1 }
for (var key of foo) {
console.log(key)
}
// 输出: Uncaught TypeError: foo is not iterable可以给一个对象设置一个迭代器,让一个对象也可以使用 for-of 循环:
var bar = {
a: 1,
[Symbol.iterator]: function() {
var valArr = [
{ value: 'hello', done: false },
{ value: 'world', done: false },
{ value: '!', done: false },
{ value: undefined, done: true }
]
return {
next: function() {
return valArr.shift()
}
}
}
}
for (var key of bar) {
console.log(key)
}
// 输出: hello
// 输出: world
// 输出: !可以看到 for-of 循环连 bar 对象自己的属性都不遍历了,遍历获取的值只和 Symbol.iterator 方法实现有关。
5. 迭代器模式总结
迭代器模式早已融入我们的日常开发中,在使用 filter、reduce、map 等方法的时候,不要忘记这些便捷的方法就是迭代器模式的应用。当使用迭代器方法处理一个对象时,可以关注与处理的逻辑,而不必关心对象的内部结构,侧面将对象内部结构和使用者之间解耦,也使得代码中的循环结构变得紧凑而优美。
观察者模式/发布-订阅模式
1. 什么是观察者模式/发布-订阅模式?
(1)观察者模式:
观察者模式(Observer Pattern)定义了一种一对多的关系,让多个订阅者对象同时监听某一个发布者,或者叫主题对象,这个主题对象的状态发生变化时就会通知所有订阅自己的订阅者对象,使得它们能够自动更新自己。
观察者模式属于行为型模式,行为型模式关注的是对象之间的通讯,观察者模式就是观察者和被观察者之间的通讯。
(2)发布-订阅模式:
在23种设计模式中没有发布-订阅模式的,其实它是发布订阅模式的一个别名,但两者又有所不同。这个别名非常形象地诠释了观察者模式里两个核心的角色要素——发布者和订阅者。
很多人在微博上关注了A,那么当A发布微博动态的时候微博就会为我们推送这个动态。在这个例子中,A就是发布者,我们是订阅者,微博就是调度中心,我们和A之间是没有直接信息来往的,都是通过微博平台来协调的,这就是发布-订阅模式。
虽然发布-订阅模式是观察者模式的一个别名,但是发布-订阅模式经过发展,已经独立于观察者模式,成为一种比较重要的设计模式。
这两种模式的最大区别就是发布-订阅模式有一个调度中心: 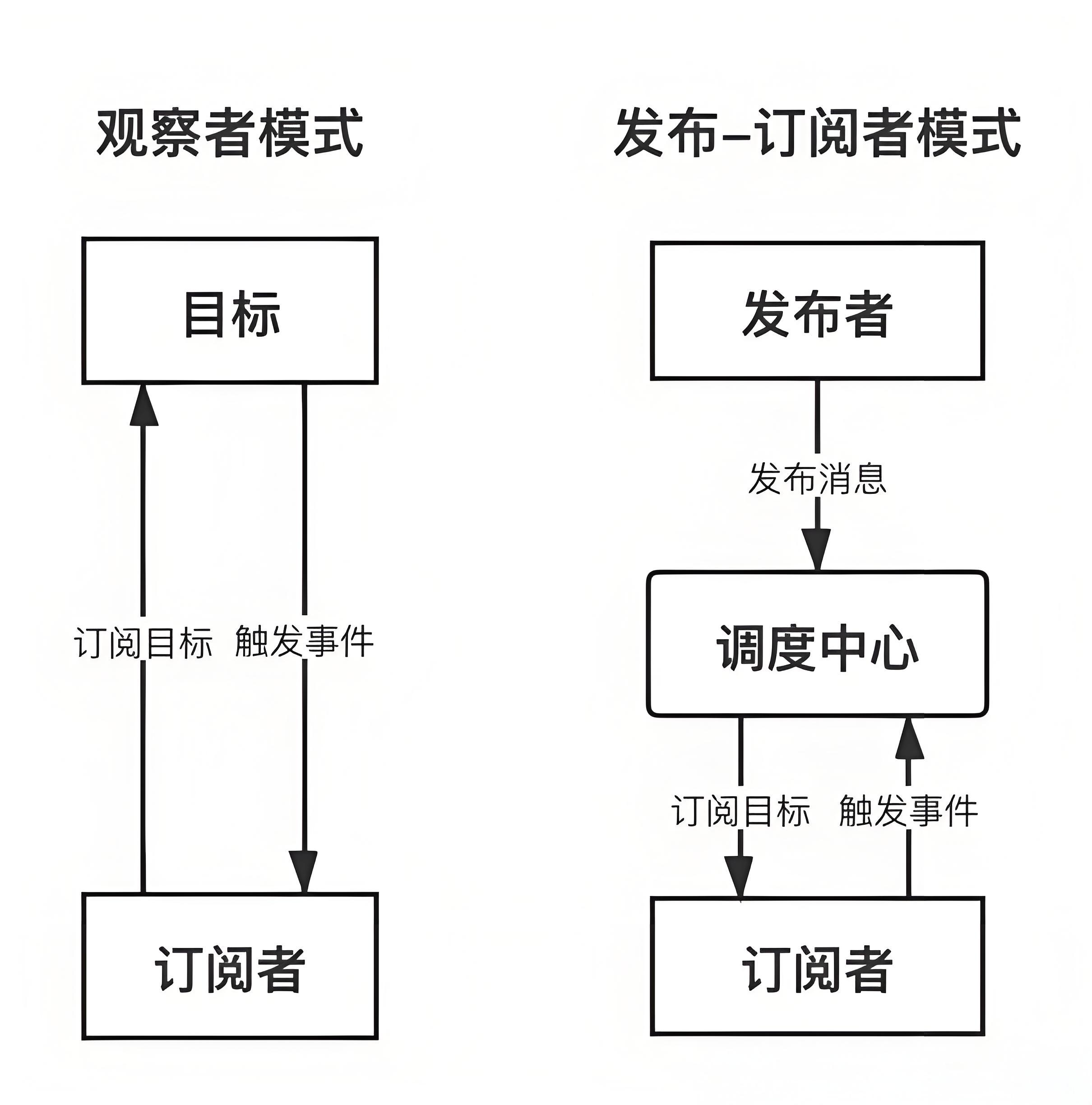 可以看到,观察者模式是由具体目标调度的,而发布-订阅模式是统一由调度中心调的,所以观察者模式的订阅者与发布者之间是存在依赖的,而发布-订阅模式则不会,这就实现了解耦。
可以看到,观察者模式是由具体目标调度的,而发布-订阅模式是统一由调度中心调的,所以观察者模式的订阅者与发布者之间是存在依赖的,而发布-订阅模式则不会,这就实现了解耦。
2. 观察者模式的实现
发布者:
// 定义发布者类
class Publisher {
constructor() {
this.observers = []
console.log('Publisher created')
}
// 增加订阅者
add(observer) {
console.log('Publisher.add invoked')
this.observers.push(observer)
}
// 移除订阅者
remove(observer) {
console.log('Publisher.remove invoked')
this.observers.forEach((item, i) => {
if (item === observer) {
this.observers.splice(i, 1)
}
})
}
// 通知所有订阅者
notify() {
console.log('Publisher.notify invoked')
this.observers.forEach((observer) => {
observer.update(this)
})
}
}订阅者:
// 定义订阅者类
class Observer {
constructor() {
console.log('Observer created')
}
update() {
console.log('Observer.update invoked')
}
}3. 发布-订阅模式的实现
在 DOM 上绑定的事件处理函数 addEventListener就是使用的发布-订阅模式。
我们经常将一些操作挂载在 onload 事件上执行,当页面元素加载完毕,就会触发注册在 onload 事件上的回调。我们无法预知页面元素何时加载完毕,但是通过订阅 window 的 onload 事件,window 会在加载完毕时向订阅者发布消息,也就是执行回调函数。
window.addEventListener('load', function () {
console.log('loaded!')
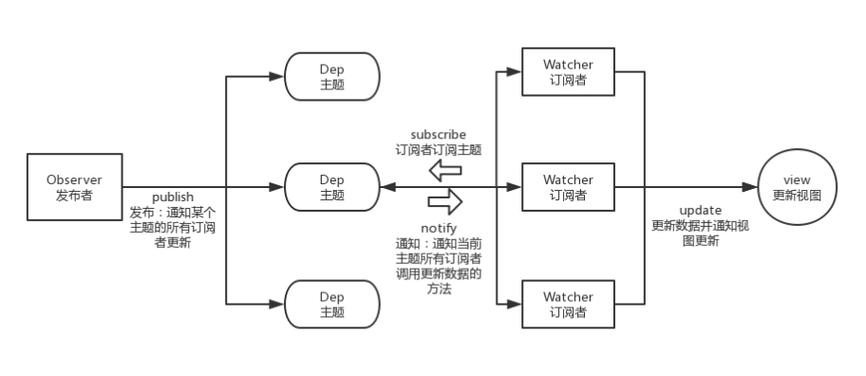
})下面就来实现一下发布-订阅模式,在实现之前,下来看几个概念:
- Publisher :发布者,当消息发生时负责通知对应订阅者
- Subscriber :订阅者,当消息发生时被通知的对象
- SubscriberMap :持有不同 type 的数组,存储有所有订阅者的数组
- type :消息类型,订阅者可以订阅的不同消息类型
- subscribe :该方法为将订阅者添加到 SubscriberMap 中对应的数组中
- unSubscribe :该方法为在 SubscriberMap 中删除订阅者
- notify :该方法遍历通知 SubscriberMap 中对应 type 的每个订阅者
class Publisher {
constructor() {
this._subsMap = {}
}
// 消息订阅
subscribe(type, cb) {
if (this._subsMap[type]) {
if (!this._subsMap[type].includes(cb))
this._subsMap[type].push(cb)
} else this._subsMap[type] = [cb]
}
// 消息退订
unsubscribe(type, cb) {
if (!this._subsMap[type] ||
!this._subsMap[type].includes(cb)) return
const idx = this._subsMap[type].indexOf(cb)
this._subsMap[type].splice(idx, 1)
}
// 消息发布
notify(type, ...payload) {
if (!this._subsMap[type]) return
this._subsMap[type].forEach(cb => cb(...payload))
}
}
const adadis = new Publisher()
adadis.subscribe('运动鞋', message => console.log('152xxx' + message)) // 订阅运动鞋
adadis.subscribe('运动鞋', message => console.log('138yyy' + message))
adadis.subscribe('帆布鞋', message => console.log('139zzz' + message)) // 订阅帆布鞋
adadis.notify('运动鞋', ' 运动鞋到货了 ') // 打电话通知买家运动鞋消息
adadis.notify('帆布鞋', ' 帆布鞋售罄了 ') // 打电话通知买家帆布鞋消息
// 输出: 152xxx 运动鞋到货了
// 输出: 138yyy 运动鞋到货了
// 输出: 139zzz 帆布鞋售罄了4. Vue中的发布-订阅模式
(1)EventBus
在Vue中有一套事件机制,其中一个用法是 EventBus。在多层组件的事件处理中,如果你觉得一层层 $on、$emit 比较麻烦,那就可以使用 EventBus 来解决组件间的数据通信问题。
eventBus事件总线适用于父子组件、非父子组件等之间的通信,使用步骤如下:
(1)创建事件中心管理组件之间的通信
// event-bus.js
import Vue from 'vue'
export const EventBus = new Vue()(2)发送事件
假设有两个兄弟组件firstCom和secondCom:
<template>
<div>
<first-com></first-com>
<second-com></second-com>
</div>
</template>
<script>
import firstCom from './firstCom.vue'
import secondCom from './secondCom.vue'
export default {
components: { firstCom, secondCom }
}
</script>在firstCom组件中发送事件:
<template>
<div>
<button @click="add">加法</button>
</div>
</template>
<script>
import {EventBus} from './event-bus.js' // 引入事件中心
export default {
data(){
return{
num:0
}
},
methods:{
add(){
EventBus.$emit('addition', {
num:this.num++
})
}
}
}
</script>(3)接收事件
在secondCom组件中发送事件:
<template>
<div>求和: {{count}}</div>
</template>
<script>
import { EventBus } from './event-bus.js'
export default {
data() {
return {
count: 0
}
},
mounted() {
EventBus.$on('addition', param => {
this.count = this.count + param.num;
})
}
}
</script>在上述代码中,这就相当于将num值存贮在了事件总线中,在其他组件中可以直接访问。事件总线就相当于一个桥梁,不用组件通过它来通信。
实现组件间的消息传递时,如果是中大型项目还是推荐使用 Vuex,因为如果 Bus 上的事件挂载过多,就可能分不清消息的来源和先后顺序,对可维护性是一种破坏,后期维护起来会很困难。
(2)Vue源码
发布-订阅模式在源码中应用很多,特别是现在很多前端框架都会有的双向绑定机制的场景,这里以现在很火的 Vue 为例,来分析一下 Vue 是如何利用发布-订阅模式来实现视图层和数据层的双向绑定。双向绑定原理图: 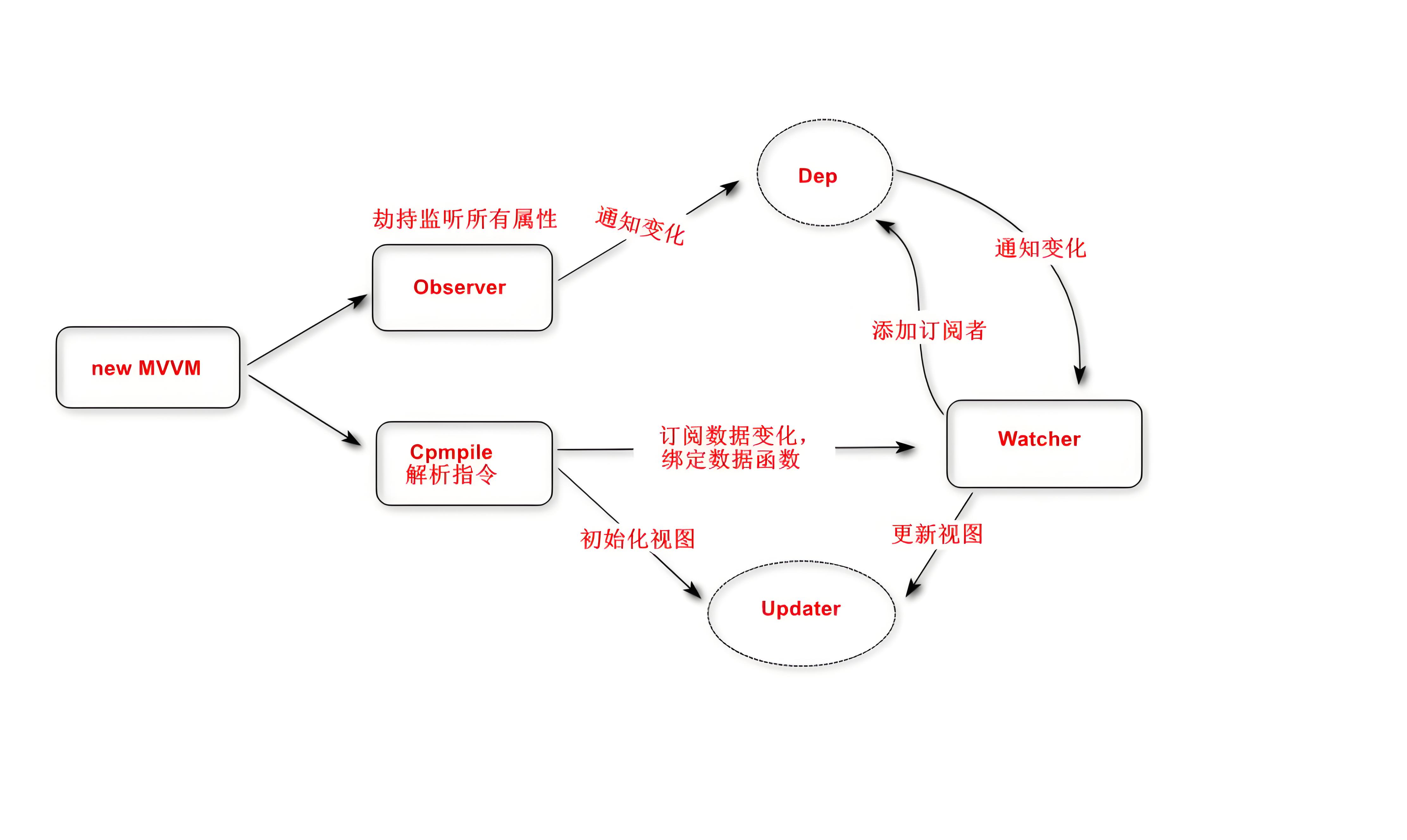
组件渲染函数(Component Render Function)被执行前,会对数据层的数据进行响应式化。响应式化大致就是使用 Object.defineProperty 把数据转为 getter/setter,并为每个数据添加一个订阅者列表的过程。这个列表是 getter 闭包中的属性,将会记录所有依赖这个数据的组件。也就是说,响应式化后的数据相当于发布者。
每个组件都对应一个 Watcher 订阅者。当每个组件的渲染函数被执行时,都会将本组件的 Watcher 放到自己所依赖的响应式数据的订阅者列表里,这就相当于完成了订阅,一般这个过程被称为依赖收集(Dependency Collect)。
组件渲染函数执行的结果是生成虚拟 DOM 树(Virtual DOM Tree),这个树生成后将被映射为浏览器上的真实的 DOM树,也就是用户所看到的页面视图。
当响应式数据发生变化的时候,也就是触发了 setter 时,setter 会负责通知(Notify)该数据的订阅者列表里的 Watcher,Watcher 会触发组件重渲染(Trigger re-render)来更新(update)视图。
Vue 的源码:
// src/core/observer/index.js 响应式化过程
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
// ...
const value = getter ? getter.call(obj) : val // 如果原本对象拥有getter方法则执行
dep.depend() // 进行依赖收集,dep.addSub
return value
},
set: function reactiveSetter(newVal) {
// ...
if (setter) { setter.call(obj, newVal) } // 如果原本对象拥有setter方法则执行
dep.notify() // 如果发生变更,则通知更新
}
})这个 dep 上的depend和 notify 就是订阅和发布通知的具体方法。简单来说,响应式数据是消息的发布者,而视图层是消息的订阅者,如果数据更新了,那么发布者会发布数据更新的消息来通知视图更新,从而实现数据层和视图层的双向绑定。
5. 观察者模式的优缺点
观察者模式有以下优点:
- 观察者模式在被观察者和观察者之间建立一个抽象的耦合。被观察者角色所知道的只是一个具体观察者列表,每一个具体观察者都符合一个抽象观察者的接口。被观察者并不认识任何一个具体观察者,它只知道它们都有一个共同的接口。 由于被观察者和观察者没有紧密地耦合在一起,因此它们可以属于不同的抽象化层次。如果被观察者和观察者都被扔到一起,那么这个对象必然跨越抽象化和具体化层次。
- 观察者模式支持广播通讯。被观察者会向所有的登记过的观察者发出通知,
观察者模式有以下缺点:
- 如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。
- 如果在被观察者之间有循环依赖的话,被观察者会触发它们之间进行循环调用,导致系统崩溃。在使用观察者模式是要特别注意这一点。
- 如果对观察者的通知是通过另外的线程进行异步投递的话,系统必须保证投递是以自恰的方式进行的。
- 虽然观察者模式可以随时使观察者知道所观察的对象发生了变化,但是观察者模式没有相应的机制使观察者知道所观察的对象是怎么发生变化的。
6. 发布-订阅模式的优缺点
发布-订阅模式最大的优点就是解耦:
- 时间上的解耦:注册的订阅行为由消息的发布方来决定何时调用,订阅者不用持续关注,当消息发生时发布者会负责通知;
- 对象上的解耦 :发布者不用提前知道消息的接受者是谁,发布者只需要遍历处理所有订阅该消息类型的订阅者发送消息即可(迭代器模式),由此解耦了发布者和订阅者之间的联系,互不持有,都依赖于抽象,不再依赖于具体;
由于它的解耦特性,发布-订阅模式的使用场景一般是:当一个对象的改变需要同时改变其它对象,并且它不知道具体有多少对象需要改变。发布-订阅模式还可以帮助实现一些其他的模式,比如中介者模式。
发布-订阅模式也有缺点:
- 增加消耗 :创建结构和缓存订阅者这两个过程需要消耗计算和内存资源,即使订阅后始终没有触发,订阅者也会始终存在于内存;
- 增加复杂度 :订阅者被缓存在一起,如果多个订阅者和发布者层层嵌套,那么程序将变得难以追踪和调试。
缺点主要在于理解成本、运行效率、资源消耗,特别是在多级发布-订阅时,情况会变得更复杂。